word2vec_seq2seq_attention_transformer_bert
word2vec_seq2seq_attention_transformer_bert
word2vec
- 优点:
- 1)由于 Word2vec 会考虑上下文,跟之前的 Embedding 方法相比,效果要更好(但不如 18 年之后的方法)
- 2)比之前的 Embedding方法维度更少,所以速度更快
- 3)通用性很强,可以用在各种 NLP 任务中
- 缺点:
- 1)由于词和向量是一对一的关系,所以多义词的问题无法解决。
- 2)Word2vec 是一种静态的方式,虽然通用性强,但是无法针对特定任务做动态优化
下采样
- 高频词:
- 1)例如the等词不会提供更多语义
- 2)训练时用不到那么多样本对
- 因此以以某种概率删掉一些词,这个概率与词出现的频数有关
负采样
- 对于负样本,只选择一部分。因为负样本的label为0,因此每次更新的参数也会较少。回忆一下我们的隐层-输出层拥有300 x 10000的权重矩阵。如果使用了负采样的方法我们仅仅去更新我们的positive word-“quick”的和我们选择的其他5个negative words的结点对应的权重,共计6个输出神经元,相当于每次只更新300*5个权重。对于3百万的权重来说,相当于只计算了0.06%的权重,这样计算效率就大幅度提高。
- 单词被选中的概率与其频度有关:

CBOW和skip-gram
- CBOW:周围词预测中心词,每次迭代都在调整周围词,因此其迭代的次数与语料库大小相同,复杂度为O(V)
- S-G:中心词预测周围词,每次迭代都在调整中心词,每个中心词需要调整K次,因此其迭代的次数为K*V次,这里K为窗口大小,复杂度为O(KV)
- 即CBOW快于S-G;而SG更适用于生僻词以及语料库较小的情况的训练,因为生僻词出现的次数少,SG能够对其进行较多次的训练
在cbow方法中,是用周围词预测中心词,从而利用中心词的预测结果情况,使用GradientDesent方法,不断的去调整周围词的向量。当训练完成之后,每个词都会作为中心词,把周围词的词向量进行了调整,这样也就获得了整个文本里面所有词的词向量。要注意的是, cbow的对周围词的调整是统一的:求出的gradient的值会同样的作用到每个周围词的词向量当中去。可以看到,cbow预测行为的次数跟整个文本的词数几乎是相等的(每次预测行为才会进行一次backpropgation, 而往往这也是最耗时的部分),复杂度大概是O(V).
而skip-gram是用中心词来预测周围的词。在skip-gram中,会利用周围的词的预测结果情况,使用GradientDecent来不断的调整中心词的词向量,最终所有的文本遍历完毕之后,也就得到了文本所有词的词向量。
可以看出,skip-gram进行预测的次数是要多于cbow的:因为每个词在作为中心词时,都要使用周围词进行预测一次。这样相当于比cbow的方法多进行了K次(假设K为窗口大小),因此时间的复杂度为O(KV),训练时间要比cbow要长。
但是在skip-gram当中,每个词都要收到周围的词的影响,每个词在作为中心词的时候,都要进行K次的预测、调整。因此,当数据量较少,或者词为生僻词出现次数较少时, 这种多次的调整会使得词向量相对的更加准确。因为尽管cbow从另外一个角度来说,某个词也是会受到多次周围词的影响(多次将其包含在内的窗口移动),进行词向量的跳帧,但是他的调整是跟周围的词一起调整的,grad的值会平均分到该词上, 相当于该生僻词没有收到专门的训练,它只是沾了周围词的光而已。
从更通俗的角度来说:在skip-gram里面,每个词在作为中心词的时候,实际上是 1个学生 VS K个老师,K个老师(周围词)都会对学生(中心词)进行“专业”的训练,这样学生(中心词)的“能力”(向量结果)相对就会扎实(准确)一些,但是这样肯定会使用更长的时间;cbow是 1个老师 VS K个学生,K个学生(周围词)都会从老师(中心词)那里学习知识,但是老师(中心词)是一视同仁的,教给大家的一样的知识。至于你学到了多少,还要看下一轮(假如还在窗口内),或者以后的某一轮,你还有机会加入老师的课堂当中(再次出现作为周围词),跟着大家一起学习,然后进步一点。因此相对skip-gram,你的业务能力肯定没有人家强,但是对于整个训练营(训练过程)来说,这样肯定效率高,速度更快。
seq2seq
encoder-decoder模型

- 其中,encoder和decoder的具体架构可选,CNN/RNN/LSTM/GRU…
- C由encoder中所有时间的隐藏状态决定,设共Tx个状态,则C = q(h1,h2,…hTx)
- decoder为一个语言模型,则
- 注意,这个C是不变的,即对于decoder中的序列,输入的C是相同的
- 局限:encoder和decoder的联系只依靠一个固定长度的语义向量c
- 语义向量可能无法完全表达encoder中整个序列的信息,且输入序列越长,此现象越严重;
- encoder中序列先输入的内容会被后输入的内容稀释掉
seq2seq
结构
- 第一种结构:将c当做decoder每一时刻的输入,如上encoder-decoder
- 第二种结构:c只作为decoder初始时刻的输入
使用
- 测试时,decoder中前序输出输入到下一个时刻
- 训练时,decoder前序输出不作为下一时刻的输入,而使用真实序列作为输入
- 端对端训练:
- 两个分模型分别训练得到最优后合在一起不一定能获得全局最优
decoding
- 本质是求条件概率
- greedy decoding:decoder中每个序列会接一层softmax,输出语料库中每个单词的概率,测试时,每次取概率最大的单词作为下一序列的输入,称为greedy decoding。
- greedy的问题:无法回退,预测出错之后会一直错下去。
- Exhaustive search decoding: 每一步都计算,设语料库大小为V,则第T时刻的时间复杂度为O(V^T)
- Beam Search decoding:
- 每次track k个最有可能的值。
- 如果遇到结束的序列,先保存,等所有序列结束后,比较其条件概率除以序列长度的最大值(为了避免倾向于选择较短的序列,除以序列长度)。
- 终止条件:序列长度阈值、可选结果个数阈值。
局限
- encoder和decoder的联系只依靠一个固定长度的语义向量c:
- 语义向量可能无法完全表达encoder中整个序列的信息,且输入序列越长,此现象越严重;
- encoder中序列先输入的内容会被后输入的内容稀释掉
应用
应用seq2seq做NMT(Neural Machine Translation)
- 优点:
- better performance:更流利;应用了更多的上下文信息;对短语相似性利用的更好
- 端对端训练
- 更少的人工
- 劣势:
- 解释性
- 更难debug
- 更难控制(比起SMT(可以直接用规则))
- 安全性
- 遗留问题:
- out-of-vocabulary words:语料库里没有的单词无法翻译
- domain dismatch:用维基百科训练的模型对Facebook不一定好用
attention
motivation
- 1)语义向量C有语义表达的瓶颈,attention可以使decoder的每个时刻与encoder相连;
- 2)attention可以使得decoder的每一步只关注encoder的特定部分。
本质思想
- target中给定一个query,计算该query与source中每个key之间的相似度,即sim(Query, Key i);然后对每个sim值进行softmax;使用softmax值来加权平均source中每个key对应的value,并得到attention score:

method
- 核心:==个性化encoder中每个时刻对decoder中每个时刻的影响,并且直接连接到encoder==:

- 参考文章attention
- decoder中每个时间点语义编码对其贡献是一样的Y1=g(C,h(0)),Y2=g(C,Y1)…
- attention中,decoder不再将整个序列编码成固定长度的语义向量C,而是根据生成的新单词计算新的Ci,使得不同时刻输入不同的C,这样就解决了单词信息丢失的问题:
- 即decoder中每个时刻的结果是上个时刻输出、该时刻状态、该时刻语义向量C的函数,而此时刻的状态为上个时刻输出、上个时刻状态以及Ci的函数。
- attention,Ci的计算为:
- 即对于decoder的每个状态Si,Ci为encoder中每个状态的hi的加权平均,其中权重为decoder中si-1与encoder中的每个隐藏状态决定(softmax)
- 整体:
$e{i j}=a\left(s{i-1}, h_{j}\right)$ 这里 $a$ 可以是内积, 即 $S i-1$ 和 $h j$ 的内积 - 原始attention论文中,encoder使用了BiRNN,因此可以获取到某个输入上下文的信息
attention score的多种计算方式
- 参考文章attention
- 本质是计算query和source中每个key的相似度或相关度:
- 点积
- cosine相似性
- MLP网络

self Attention/ intra Attention
- Self Attention顾名思义,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。
- 例如可以捕捉同一个句子中的句法特征和语义特征
- 引入Self Attention后会更容易捕获句子中长距离的相互依赖的特征,因为如果是RNN或者LSTM,需要依次序序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。
- 此外,可以增加计算并行化,原因是对于self-attention来说,不需要等待序列生成。
attention的好处
- 解决了bottleneck问题
- 允许decoder直接获取到source的信息,而不是经过一个bottleneck
- 个性化encoder中每个时刻的状态对当前decoder状态的影响
- 类似于VGG中的残差,有助于解决vanish gradient
- 增强了解释性
- 差不多算是一种软对齐
- 并行:https://www.jianshu.com/p/6b698bb6a486
- encoder:层间无法并行,层内可以同时feed所有输入向量,同时更新梯度,实现并行。而RNN只能并行实现所有时刻的输入,而不能实现梯度的并行(梯度需要从n层到n-1层)。
- decoder:第n个输出依赖第n-1个输出,因此不可以并行。
Transformer
- Paper: attention is all you need
- 初衷:解决传统RNN等序列模型中无法并行化的问题;CNN可以并行但无法用于变长序列
Encoder and decoder stacks
模型结构
- 简化为两层的Encoder Decoder示意图:

- 注意是Encoder的输出连到decoder中的encoder-decoder attention层,即第六层的encoder输出的每个序列加权求attention的source
Encoder
- 由6层组成,每层由2个子层组成,每个子层都使用了residual(残差)连接以及加入了正则化层,即每个子层的输出为LayerNorm(x+Sublayer(x)),x就是这个层的输出。为了确保连接,所有sub-layer和embedding layer的输出维度相同。
- 第一个子层为multi-head self-attention mechanism
- 第二个子层为全连接前馈网络。
Decoder
- 6层组成。每层三个子层,除与Encoder相同的两层外,加入了一个masked multi-head self-attention。同样适用残差操作。
Layer Normalization
Batch Normalization
- 是在Batch size方向的正则化,即对于一个向量(样本)的每个位置,求其在Batch Size上的均值和方差,并做正则化。
LN
- 在每个样本上计算均值和方差
Attention
Scaled Dot-Product Attention
- query Q和keys K的维度为dk,values V的维度为dv(意思是一个query或一个key,即一个时刻的key的维度是dv)。设source有s个时刻,target有t个时刻。有:Q—t*dk, K—s*dk, V—s*dv
- 指定了一种方法来计算query Q和key K之间的相似性:. 这里比平常的点积相似度多除一个{\sqrt{d_{k}},dk是K的维度,原因为:dk很大的时候,点积得到的相似度值非常大,因为每个相似度都是dk个乘机的和,此时相似度之间差异会相对比较小,即相似度的梯度区域会比较小。
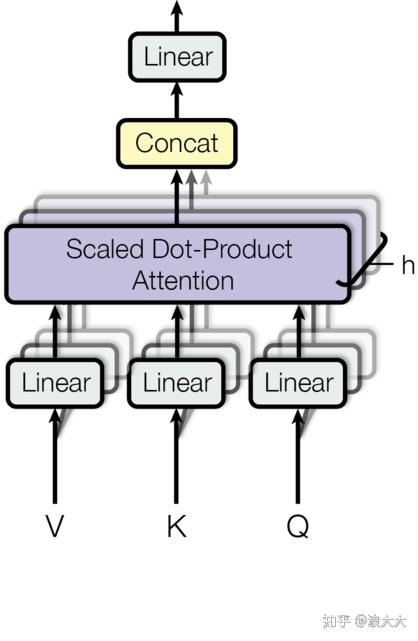
multi-head attention
具体计算过程很繁琐,参照文中的图解
- 多头作用:获取不同子空间的信息;增加并行化
- 单头
- embedding为dmodel=512维度,对其做线性映射以Q为例:Q * W = t dmodel dmodel dk = t dk,即每个query从dmodel到了dk=64维度,即新的Q为dk=64维
- Q * K^T = t * dk* dk s = t s
- softmax(Q * K^T / sqrt(dk)) = t * s,即以行做softmax
- softmax * V = t * s * s * dv = t * dv
- 多头self-attention:做多个单头,每个单头的映射矩阵随机初始化,然后得到h个attention得分,transforms中用了h=8个头,即8个t * dv 的attention得分向量
- 多头self-attention输入前馈神经网络:先把8个矩阵按列拼接: t * (h dv);再随机初始化一个(h dv) * dmodel的矩阵,最后结果为t * dmodel,最终得到dmodel是使得其跟原始的输入同纬度,方便相加操作(残差中要用到)
Attention在transform中的应用
- 有三种不同的应用:
- 在encoder-decoder attention层,query来自于前序decoder层,key和value来自于encoder的输出。This allows every position in the decoder to attend over all positions in the input sequence。是典型的seq2seq中的attention。
- encoder中的self-attention层,key/value/query都来自于之前层(大层,不是子层,也不是attention中的序列)的输出,encoder中每个位置可以attend to之前层的输出
- decoder中的self-attention层,用了mask来掩盖某些值,使其在参数更新中不产生效果。这里self attention在应用的时候
- Padding Mask: 每个batch输入的序列长度不同,因此要对收入序列对齐。较短序列在后面填充0,较长序列只截取左边内容。填充0时,会把这些位置的值加上负无穷,经过softmax之后这些地方的概率会接近于0(e的负无穷大次方为0).
- Sequence Mask: 使得decoder不能看见未来的信息。做法为:使用一个上三角全为0的矩阵
Position-wise Feed-Forward Networks
- 两层:两个线性变换和一个ReLU激活输出:
Embedding and Softmax
Position Encoding
- 模型中没有使用循环神经网络或者卷积,所以位置信息需要被编码Position Encoding,该向量和embedding的维度一致,并把该向量与embedding相加输入到下一层。
- 其中pos是位置,i是向量中每个值的index。即在偶数位置使用正弦编码;奇数位置,使用余弦编码。也就是说对于向量的同一个index,每个pos处的向量被编码后是一个sin函数,该函数的波长为2π~10000*2π。选择这个函数的目的是因为这个函数能学习到相对位置,即pos+k可以由pos的线性函数得到,这些相对位置的信息会使用在self-attention中。
为何使用self-attention
- 简单来说,我们需要一个对原序列进行编码以提取信息,在进行编码的过程中需要考虑:
- 每层的计算复杂度。
- 最小序列操作,即并行化的程度。
- 网络中远程依赖关系之间的路径长度(path length between long-range dependencies in the network)。路径越短越能学习到长距离的依赖关系。
| Layer Type | Complexity per Layer | Sequential Operations | Maximum Path Length |
|---|---|---|---|
| Self-Attention | O(n^2*d) | O(1) | O(1) |
| Recurrent | O(n*d^2) | O(n) | O(n) |
| Convolutional | O(k*n*d^2) | O(1) | O(logk(n)) |
| Self-Attention(restricted) | O(r*n*d) | O(n/r) | O(1) |
n: 序列长度,d: 表达维度,k: 卷积核size,r: Self-Attention(restricted)中的领域size
训练
正则化
- Residual Dropout
- Attention Dropout: embeddings + positional encodings
- Label Smoothing
decoder
- beam search
总结
- attention代替了传统的RNN层。
- RNN每层的信息会随着序列的增加而衰减,因此难以获得较长序列跨度的信息;attention层对其他词的信息不取决于距离而取决于相关性/表示的相似度
- Transform可以获得双向信息
- 并行化
- attention无需参数,只使用超参数,也即无监督,使得模型很简洁
- self-attention:使用dot-product的相似性计算方式,实际上是一种无监督求解相似性的方式。并行化非常好。
- 为何点积可以求得相似性:点积可以用来求解两向量的夹角。
- decoder第一层的输入是什么
- decoder中的attention层的key和query
- mask具体
- 为何不用BN用LN,LN的作用是:BN使得输入到下一层的样本分布为正态分布,也就是特征的每个维度是正则化的,以改善训练,加速收敛(独立同分布的数据可以简化常规机器学习模型的训练、提升机器学习模型的预测能力);LN使得每个样本的不同index处的分布为正态分布
Transformer VS CNN
- CNN可以并行化输出序列
- CNN的感受野有限,不能感知所有上下文
- CNN每层的卷积权重共享,而Attention每一个decoder对应的attention是不一样的
Bert(Bidirectional Encoder Representations from Transformers)
两个任务
- Masked Language Model(MLM)
- Next Sentence Prediction
模型结构
- L: transformer blocks; H: hidden size; A: self-attention heads;
- Bert-base: L=12, H=768, A=12, total-Params=110M
- Bert-large: L=24, H=1024, A=16, total-Params=340M
- 输入输出表达:
- sentence:一段连续文本,并不是语言学中的句子
- sequence:BERT的输入tocken sequence,1 sentence或2 sentences(2 sentences用于后续的NSP)
- 使用tocken个数为30000的WordPiece embeddings,每个sequence的第一个tocken为[CLS]
- 不同sentence区分的方式:1. 通过[SEP]分隔;2. 学习一个embeddings,不同的sentence用不同的embedding来区分
- 一个给定的tocken,其input representation是相应的tocken、segment和position embeddings的和

Pre-training BERT
- 两种无监督训练任务
Masked LM
- 在每个sequence中随机mask 15%的wordpiece tockens
- 缺点:[MASK] tocken不会出现在fine-tuning中,所以会造成pre-training和fine-tuning的mismatch。解决:not always replace “masked” words with the actual [MASK] token:
- 80%的时候用[MASK] tocken
- 10%的random tocken
- 10%的unchanged token
- Transformer encoder不知道它将被要求预测哪些单词或哪些单词已被随机单词替换,因此它被迫保持每个输入token的分布式上下文表示。此外,因为随机替换只发生在所有token的1.5%(即15%的10%),这似乎不会损害模型的语言理解能力。
Next Sentence Prediction
LM无法获取两句之间的相关性
- label:每个样本对AB,如果50%的时间B是A的下一句,则为IsNext,否则NotNext
Pre-training data
BooksCorpus (800M words) (Zhu et al., 2015) and English Wikipedia (2,500M words)
使用文件级的语料库而不是语句级的,这样次啊能够提取到长的连续语句
word2vec vs glove vs elmo vs gpt vs bert
- word2vec, Glove只与预训练预料有关
- ELMo
- 属于Context word embedding
- ELMo不是对每个单词使用固定嵌入,而是在为其中的每个单词分配嵌入之前查看整个句子,它使用在特定任务上训练的双向LSTM来创建这些嵌入
- 训练时,采用语言模型的方法
- OpenAI Transformer
- 使用无attention层的decoder
- 只使用了单向信息
- pre-train和fine-tuning不匹配,例如对于多句输入的情况
- BERT
- 使用了encoder
- Masked LM解决了只使用单向信息的问题
- 使用NSP来解决pre-train和fine-tuning不匹配的问题