CS224WLec2-Traditional Methods for ML on Graphs
Pipeline
design features for nodes/link/graphs —> obtain features for all data —> train an ML model —> apply the model
Feature design
- focus on undirected graphs
Node Features
centrality中心性
- Degree counts #(edges) that a node touches
- degree只考虑neibors数量,不考虑neibor的不同重要性
Eigenvector centrality
- 定义:节点的重要性由邻居节点的重要性决定。节点v的centrality是邻居centrality的加总,N(v)为v的neibors集合
可以将其写为矩阵形式,得到 $ \lambda c=A c $ ,A为邻接矩阵,$ \lambda{max} $ 总为正且唯一,因此可以将其对应的$ c_{max} $作为eigenvector
betweenness centrality
- 如果一个节点处在很多节点对的最短路径上,那么这个节点是重要的
closeness centrality
- 一个节点距其他节点之间距离最短,那么认为这个节点是重要的。分母:该节点与其他节点的最短距离之和。
clustering coefficient
- Clustering coefficient counts #(triangles) that a node touches.
- 节点的neighbors两两连接的情况 —》neighbor总跟该节点连接着,neibor两两连接就能构成三角形 —》反映了该节点和其neighbors是否能聚为一类的情况


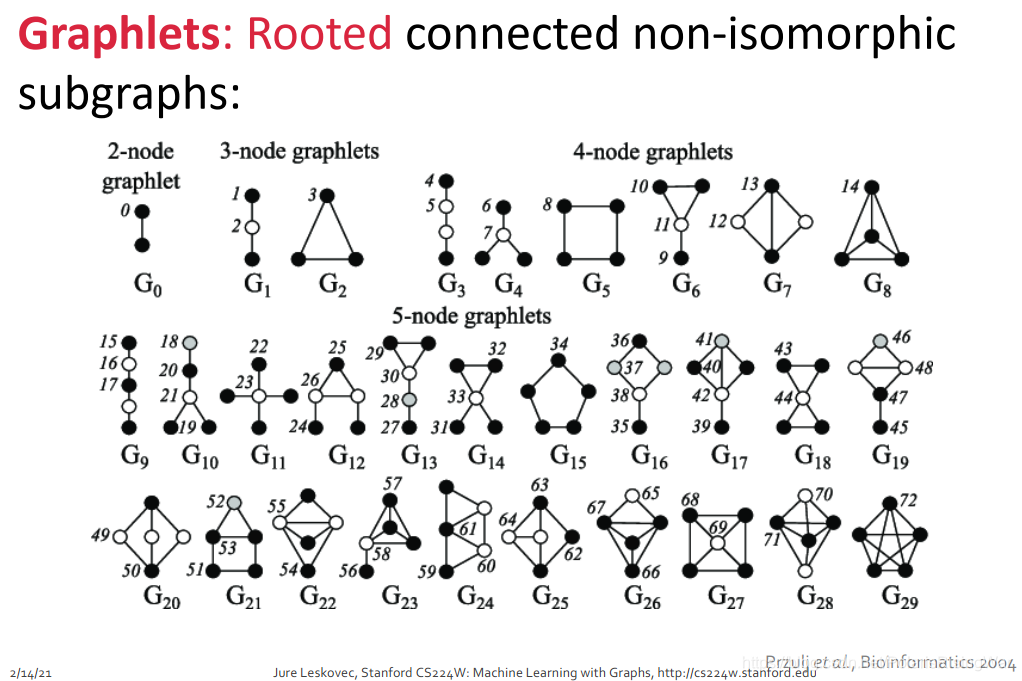
Graphlets
- Rooted connected induced non-isomorphic subgraphs, 有根连通异构子图
- graphlet为给定图的子图,需要满足四个条件
- 1.rooted: 同一个结构,指定的根节点不同,属于不同的结构
- 2.connected: 连通图
- 3.induced subgraphs: 是induced得到的subgraphs, 即该子图包括的nodes在原图中的所有link都应该包括在子图中
- 4.non-isomorphic: 异构图
- 对3的解释:
- graphlet为给定图的子图,需要满足四个条件

- 不给定图时,节点数为2-5情况下一共能产生如图所示73种graphlet。这73个graphlet的核心概念就是不同的形状,不同的位置。图中标的数字代表graphlet的id(根节点可选的位置)。例如对于$ G_0 $,两个节点是等价的(对称的),所以只有一种graphlet;对于$ G_1 $,根节点有在中间和在边上两种选择,上下两个边上的点是等价的,所以只有两种graphlet。其他的类似。
- Graphlet Degree Vector (GDV): A count vector of graphslets rooted at a given node
- GDV counts #(graphlets) that a node touches

- 以v作为节点的有根连通异构子图共4个,分别为a b c d为节点的子图。a有两种情况;b一种情况;c不存在是因为graphlet是induced subgraph,c可以induce为b;d有两种情况。所以得到的GDV为[2, 1, 0, 2]
- 考虑2-5个节点的graphlets,我们得到一个长度为73个坐标coordinate(就前图所示一共73种graphlet)的向量GDV,描述该点的局部拓扑结构topology of node’s neighborhood,可以捕获距离为4 hops的互联性interconnectivities
- 相比节点度数或clustering coefficient,GDV能够描述两个节点之间更详细的节点局部拓扑结构相似性local topological similarity。
Summary
- 节点的重要性importance-based: node degree/centrality
- 节点邻域的拓扑结构structure-based: node degree/clustering cofficient/graphlet count vector
Link features & Link-level prediction
- diagram: predict new links based on the existing links. At test time, predict ranked top k node pairs
- 所以需要为pair of nodes设计特征
两类任务
- predict缺失的links
- 给定t0时刻的links,预测t1时刻的links
Distance-based features
- 一个pair of node的最短距离、最长距离等
- 无法得知其邻域的overlap
Local neighborhood overlap
- 某两个节点其邻域的overlap -》两节点邻域没有交集其overlap为0
- 1.common neighbors: 求交集,
- 2.Jaccard’s coefficient: IoU
- 3.Adamic-Adar index: 两节点交集的点的1/log(degree)之和
Global neighborhood overlap
- 使用整张图的结构来表示两节点的关系
- Katz index: 计算两个节点间距离为i时有多少条通路,并穷举i,求通路数之和
- 邻接矩阵A的k次幂可以表示距离为k时通路的数量:$A_{u v}^{l}$即距离为l的通路数量
- Katz index:
- 闭环形式:
Graph features
focus on the Graph kernels
- 图G和G’,其kernel为K(G, G’),且可以写成: ,其中G的特征向量为$ \boldsymbol{f}_{G} $,称这种形式的特征表达为Kernel features
- 需要满足:
- kernel K(G, G’)能够表达G和G‘的相似性
- kernel matrix
- 存在一种特征表达$\phi(\cdot)$满足$K\left(G, G^{\prime}\right)=\phi(\mathrm{G})^{\mathrm{T}} \phi\left(G^{\prime}\right)$
- 最简单的,kernel可以是图不同degree的node个数组成的vector
Graphlet kernel
- 与node level的不同:
- 不要求连通性,点个数在继续,不需要彼此能联通
- 不要求rooted,异构即可
- 具体的:
- 先确定graphlet的node个数k
- 求k个node的graphlets list:
- 求graphlets list中每个Graphlet在图中出现了几次,并构成vector: for

- problem1: graph不一样,kernel的值会skewd
- solution: normalize
- problem2: 对size n的graph求size k的graphlet需要$n^{k}$
- problem3: 图的degree上界是d,则需要$O\left(n d^{k-1}\right)$
- problem4: 最糟糕的情况是判断一个图是不是另一个图的子图是np-hard问题(不确定性多项式hard问题,不能确定能不能在n的多项式内的复杂度完成)
Weisfeiler-Lehman Kernel
- color refinement方法
- 也需要定义一个k,含义为step
- 每一个step都用到了上一个step的值,而第一个step中,每个节点v的c(v)与其邻域有关,所以 第k个step能够得到v的k-hop邻域
- example, k=1, G1和G2的vector都是[6,2,1,2,1]


- 时间复杂度:#(edges)的线性
- 本质:bag of colors,colors代表了n-hop(n=1…k)的邻域结构
- 与Graph neural network很类似。?