CV-CNN
[TOC]
卷积神经网络
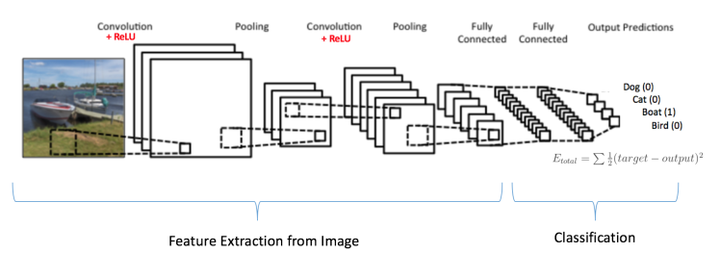
- 卷积神经网络大致就是covolutional layer, pooling layer, ReLu layer, fully-connected layer的组合,例如下图所示的结构。
图片的识别
- 生物所看到的景象并非世界的原貌,而是长期进化出来的适合自己生存环境的一种感知方式
- 画面识别实际上是寻找/学习动物的视觉关联形式(即将能量与视觉关联在一起的方式)
- 画面的识别取决于:
- 图片本身
- 被如何观察
- 图像不变性:
- 当出现上述variance时,前馈无法做到适应,即前馈只能对同样的内容进行识别,若出现其他情况时,只能增加样本重新训练
- 解决方法可以是让图片中不同的位置有相同的权重——共享权重
CNN
局部连接
- 空间共享(引入的先验知识)
- 局部连接(得到的下一层节点与该层并非全连接)
- depth上是全连接的
每个filter会在width维, height维上,以局部连接和空间共享,并贯串整个depth维的方式得到一个Feature Map。
示例
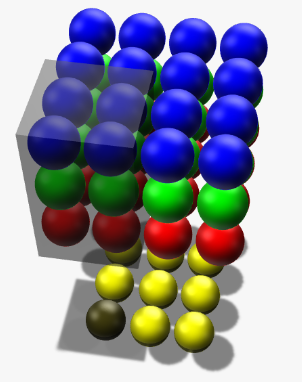
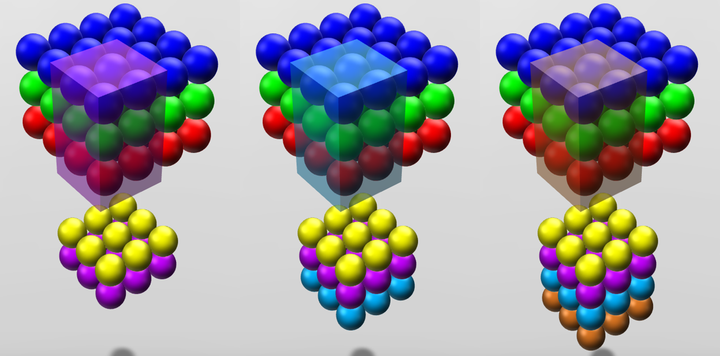
- 在输入depth为1时:被filter size为2x2所圈中的4个输入节点连接到1个输出节点上。
- 在输入depth为3时:被filter size为2x2,但是贯串3个channels后,所圈中的12个输入节点连接到1个输出节点上。
- 在输入depth为n时:2x2xn个输入节点连接到1个输出节点上。
三个channels的权重并不共享。 即当深度变为3后,权重也跟着扩增到了三组。
zero padding
有时为了保证feature map与输入层保持同样大小,会添加zero padding,一般3*3的卷积核padding为1,5*5为2
Feature Map的尺寸等于(input_size + 2 *padding_size − filter_size)/stride+1
形状、概念抓取
- 卷积层可以对基础形状(包括边缘、棱角、模糊等)、对比度、颜色等概念进行抓取
- 可以通过多层卷积实现对一个较大区域的抓取
- 抓取的特征取决于卷积核的权重,而此权重由网络根据数据学习得到,即CNN会自己学习以什么样的方式观察图片
- 可以有多个filter,从而可以学习到多种特征
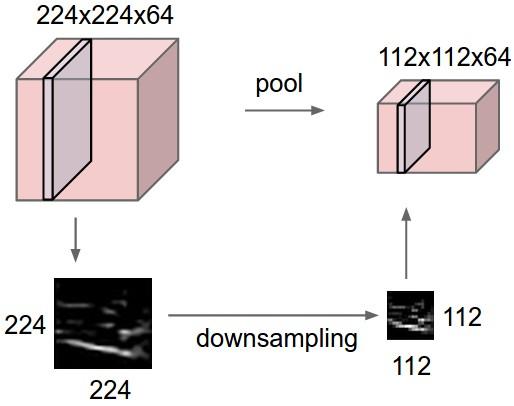
- pooling的主要功能是downsamping,有助减少conv过程中的冗余
全连接
- 当抓取到足以用来识别图片的特征后,接下来的就是如何进行分类。 全连接层(也叫前馈层)就可以用来将最后的输出映射到线性可分的空间。 通常卷积网络的最后会将末端得到的长方体平摊(flatten)成一个长长的向量,并送入全连接层配合输出层进行分类。
一些变体中用到的技巧
- 1x1卷积核:选择不同的个数,用来降维或升维
- 残差
所有的这些技巧都是对各种不变性的满足